
Databricks pre prácu prácu s dátami poskytuje tri rôzne prostredia tiež nazývané ako persony: Databricks SQL, Databricks Machine Learning a Databricks Data Science & Engineering.
Databricks SQL poskytuje jednoduché prostredie pre analytikov, ktorí potrebujú spúšťať SQL dopyty nad ich dátovým jazerom (angl. data lake), vytvárať vizualizácie rôznych typov na preskúmanie výsledkov SQL dopytov z rôznych perspektív alebo z jednotlivých vizualizácii vytvárať celé dashboardy.
Databricks Machine Learning je integrované prostredie poskytujúce služby pre sledovanie experimentov, trénovanie modelov, feature development a podobne. O možnostiach využitia Databricks na strojové učenie a o samotnom strojovom učení si povieme viac v ďalších článkoch.
Databricks Data Science & Engineering poskytuje interaktívny workspace, ktorý umožňuje spoluprácu dátových inžinierov, dátových vedcov a analytikov. A práve toto je persona, ktorú si priblížime v tomto článku.
Workspace
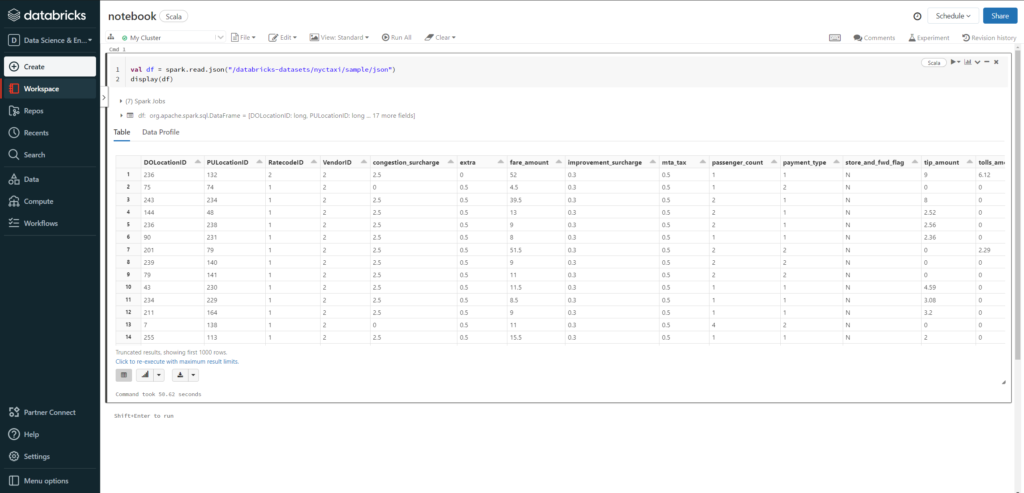
Kód vo workspace je organizovaný do notebookov. Notebook je v podstate kolekcia spustiteľných buniek – command-ov. Programovanie v notebooku znamená hlavne vytváranie a spúšťanie buniek. Každý notebook má toolbar, ktorý nám umožňuje spravovať notebook a vykonávať v ňom rôzne akcie, a jednu alebo niekoľko buniek. Na pravej strane bunky sa nachádzajú tlačidlá akcií, aj keď väčšinu vecí, ako napríklad spustenie bunky, je možné vykonať klávesovými skratkami. V tomto prípade Ctrl + Enter. Notebooky vo workspace sú usporiadané v adresárovej štruktúre.
Programovanie v Databricks
Aby sme mohli začať programovať v Databricks, musím vytvoriť notebook. Najjednoduchší spôsob je kliknúť na tlačidlo Create, vymyslieť názov a rozhodnúť sa, ktorý jazyk chceme používať – áno, Databricks umožňuje programovať v štyroch rôznych jazykoch: Scala, Python, R a SQL. A čo viac, každá bunka v notebooku môže byť napísaná v inom jazyku. Okrem týchto štyroch jazykov, Databricks umožňuje používať aj markdown pre jednoduché vytvorenie dokumentácie priamo v notebooku.
Znovupoužiteľnosť kódu
Znovupoužiteľnosť kódu a vytváranie zdieľaných knižníc je dôležitým aspektom programovania. Databricks poskytuje dve možnosti ako využiť kód z iného notebooku. Prvou možnosťou je využitie magického %run príkazu, ktorý vloží jeden notebook do druhého. Túto možnosť využijeme hlavne na modularizáciu kódu. Hneď ako zavoláme notebook pomocou %run príkazu, je volaný notebook okamžite celý spustený a všetky jeho funkcie a premenné sú dostupné vo volajúcom notebooku.

Komplementom k %run je notebook workflows. Táto funkcionalita umožňuje spustiť iný notebook veľmi podobným spôsobom ako je volanie funkcie. Volanému notebooku predáme parametre a tento notebook môže po skončení vrátiť hodnotu naspať do volajúceho notebooku. Na rozdiel od %run príkazu môže byť spustenie notebooku podmienené.
Kolaborácia
Pri práci v tíme sa nevyhneme spoluprácu na kóde notebooku. V Databricks máme niekoľko možností na spoluprácu. Zdieľaný notebook umožňuje vhodným nastavením oprávnení zdieľať jeden a ten istý notebook medzi viacerými programátormi, ktorí môžu na notebooku pracovať v reálnom čase. Tento spôsob sa vynikajúco hodí v prípade, kedy viacerí ľudia pracujú na spoločnom cieli. Nevýhodou tohto prístupu je, že okrem zdieľaného notebooku aj zdieľaný aj kontext a s tým spojené možné nechcené prepisovanie premenných a stavu. Riešením tohto problému je naklonovanie notebooku, čo je vlastne vytvorenie jeho nezávislej kópie. Alternatívou ku klonovaniu notebooku je možnosť notebook exportovať a znovu importovať do iného (alebo aj rovnakého) workspacu. Samostatnou kapitolou je podpora pre repozitáre, ktorá umožňuje pripojiť workspace ku Gitu a tak využívať VCS podobne ako sme zvyknutý z iných prostredí.
Notebook poskytuje veľmi dobrú podporu na prácu s bunkami – ako je presúvanie, pridávanie alebo mazanie. Chýba tu ale podpora pre automatické dopĺňanie, našepkávanie, preklikávanie, refaktorovanie a ďalšie funkcie, na ktoré sú programátori zvyknutí a teda nenahradí klasické IDE.
Vizualizácia dát
Jednou z veľkých výhod práce v notebooku je možno pohodlne vizualizovať dáta. Databricks ponúka široké spektrum grafov s rôznymi možnosťami.
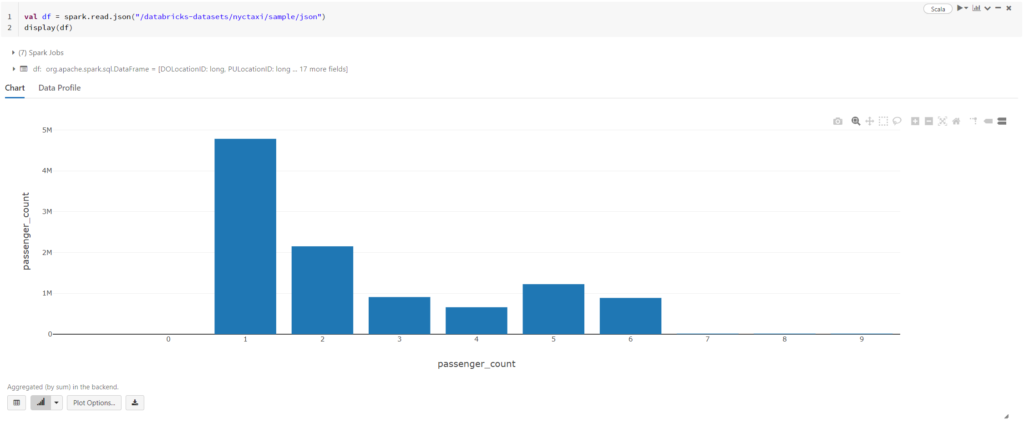
Pre príklad predpokladajme, že máme taxi službu a radi by sme zakúpili niekoľko nových áut. Premýšľame nad otázkou, aké veľké auta zvoliť a či má zmysel zaradiť do našej ponuky aj viac-miestne vozidlo prípadne rovno mikrobus. Jednoduchá vizualizácia nášho datasetu nám pomôže rozhodnúť sa. Z grafu rýchlo vidíme, že najčastejšie sú naše služby využívané práve jedným zákazníkom. Na druhej strane, počet skupín väčších ako 6 ľudí je zanedbateľný. Na základe týchto zistení zakúpime radšej iba jedno väčšie vozidlo a peniaze investujeme do viacerých menších áut.
Klastre
Aby sme mohli notebook spustiť, musí byť notebook pripojený ku klastru. To znamená, že sa na klastri vytvorí kontext, v ktorom je uložený stav REPL-u (read–eval–print loop, v podstate akýsi interaktívny shell) pre každý zo štyroch podporovaných jazykov. Po spustení bunky je jej obsah odoslaný do príslušného REPL-u, kde sa kód vykoná. Pretože každý jazyk má svoj vlastný REPL nie sú premenné a funkcie definované v jednom jazyku dostupné v inom. Stav môže byť zdieľaný len cez externé zdroje, ako napríklad súbory alebo DBFS.
Databricks klaster je množina výpočtových zdrojov spolu s konfiguráciou na ktorých je možné spustiť úlohy ako je strojové učenie, ETL procesy, analýzy a podobne.
Možnosť vytvoriť a spustiť celý klaster na pár klikov je jednou z hlavných výhod Databricks. Užívateľské rozhranie umožňuje zvoliť verziu Apache Spark-u a veľkosť a počet jednotlivých uzlov klastra. Jediné obmedzenie je, že veľkosť uzlov je viazaná na veľkosť dostupných virtuálnych mašín v cloude. Okrem UI je možné spravovať klastre aj cez API.
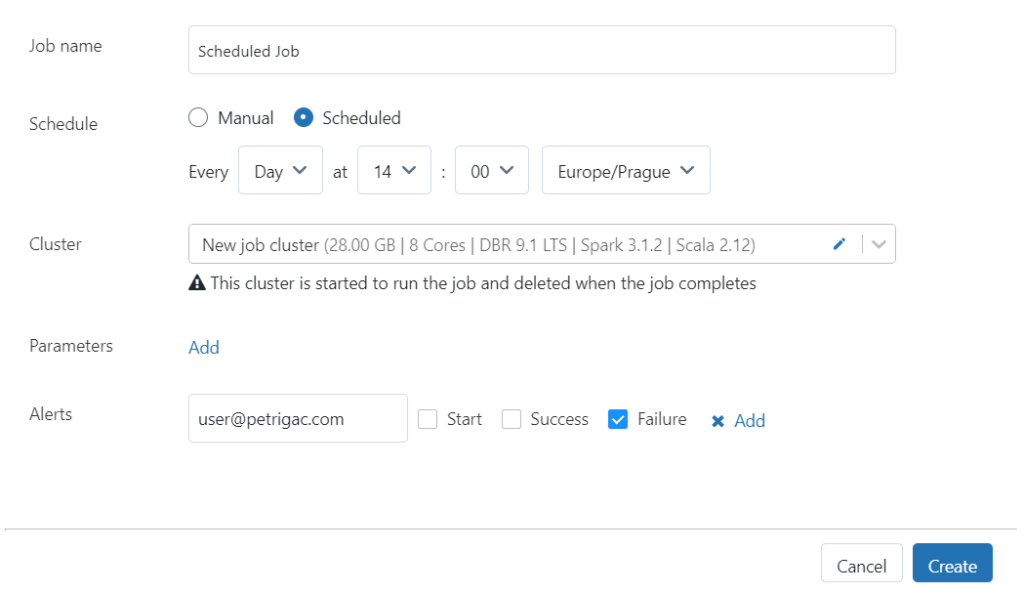
Vo všeobecnosti Databricks rozlišuje dva typy klastrov. Prvým je all-purpose alebo interactive klaster. Tento typ klastra umožňuje interaktívnu prácu v notebooku a podporuje všetky možnosti, ktoré sme si spomenuli vyššie ako je vizualizácia dát, kolaborácie alebo náhodná analýza a prístup k dátam. Na druhej strane, notebook môže obsahovať aj ETL logiku, ktorú chceme zautomatizovať. Na tieto účely sa výborne hodí job klaster. Databricks takýto klaster vyrobí na začiatku úlohy a automaticky zruší po jej skončení. Takáto úloha môže byť vytvorená ako naplánovaná úloha, kedy chcem isté operácie spúšťať pravidelne alebo môže byť vytvorené externým nástrojom ako je napríklad aktivita v Azure Data Factory.
Kde sú dáta?
Celý čas hovoríme o dátach, práci s dátami, vizualizácií a tak ďale,j ale nepovedali sme si jednu zásadnú vec, a to, kde tie dáta vôbec sú uložené. Databricks pracuje s Databricks súborovým systémom – DBFS (Databricks File System). DBFS je distribuovaný súborový systém, ktorý je namontovaný (nenašiel som lepší preklad pre mount) priamo do Databricks Worspace-u a je dostupný na celom Databricks klastri. DBFS je abstrakciou nad škálovateľným Object Storage a poskytuje niekoľko výhod.
- Súbory uložené do DBFS ostatnú dostupné aj po ukončení práce a vypnutí klastra
- Interakcia so súbormi je v sémantike adresárov a súborov namiesto URL
- DBFS umožňuje namountovať ďalšie Object Storage-e a tak pristupovať k dátam bez vyžadovania prístupových údajov
Object Storage je technológia, ktorá umožňuje pristupovať k dátam a manipulovať s dátami ako s diskrétnymi jednotkami nazývanými objekty. Objekt môžu byť textové dáta, excelový súbor, obrázok, video či čokoľvek iné. Všetky dáta sú uložené v plochej štruktúre a neexistuje tu žiadna adresárová hierarchia. Objekty častokrát obsahujú metadáta. Na identifikáciu objektu sa nepoužíva názov a cesta, ale každý objekt ma unikáty identifikátor. Prístup k súborom je možný len cez aplikačné rozhranie, napríklad URL.
Koreňový adresár DBFS je vytvorený počas vytvárania workspace-u a aj keď je možné do neho zapisovať, nie je určený pre produkčné dáta. Dáta by mali byť uložené v externom úložisku, ktoré je namontované do /mnt adresára.
Namontovanie Object Storage-u do DBFS umožňuje pristupovať k objektom rovnako ako by boli na lokálnom súborovom systéme.
Databricks umožňuje stiahnuť výsledky výpočtu priamo z UI bez nutnosti ukladania do DBFS. Táto možnosť je podporovaná len pre export do CSV a počet riadkov je limitovaný na jeden milión. Tiež nie je možno exportovať vnorené štruktúry.
Databricks zadarmo
Aj keď je Databricks primárne určený pre prostredie cloudu a je dostupný v Azure, AWS a GCP tak na stránke https://community.cloud.databricks.com je dostupná komunitná verzia, ktorá je zadarmo. V porovnaní s platenou verziou je komunitná verzia osekaná o niektoré vlastnosti (napríklad nie je dostupná Databricks SQL persona) a niektoré možnosti sú obmedzené (počet klastrov je obmedzený na jeden, nie je možné zvoliť veľkosť klastra a podobne). Napriek drobným nevýhodám je komunitná verzia výborný spôsob, ako si vyskúšať pracovať s Apache Spark, Databricks a veľkými dátami.
Odkazy do internetu
- https://docs.microsoft.com/en-us/azure/databricks/scenarios/what-is-azure-databricks
- https://community.cloud.databricks.com
- https://www.youtube.com/watch?v=7xzomULtqwY&ab_channel=AdvancingAnalytics
- https://docs.databricks.com/data/databricks-file-system.html
- https://docs.databricks.com/notebooks/notebooks-manage.html